
ChatGPT was born, GPT4 is more “smart”
On November 30, 2022, OpenAI, an American artificial intelligence research company, released the artificial intelligence chat robot ChatGPT, which became popular all over the world shortly after its launch. In just 5 days, the number of registered users of ChatGPT exceeded 1 million, and the number of monthly active users exceeded 100 million by the end of January 2023, making it the fastest growing consumer application in history. From the perspective of user experience, ChatGPT can not only achieve smooth text chat, but also be competent for relatively complex language tasks such as translation, poetry, news writing, report making, and coding.
However, technological progress does not stop. Just over three months later, on March 15, 2023, OpenAI released the latest “upgraded version” of ChatGPT – the GPT4 model, which once again detonated social media. Compared with ChatGPT, GPT-4 has a stronger image recognition ability, and the upper limit of text input has been raised to 25,000 characters. It can answer users’ questions more smoothly and accurately, and can write lyrics and creative texts, and its style is changeable. Experiments show that GPT-4 performs at a level comparable to humans on some professional tests and academic benchmarks.
Yes, it has become more “smart”. Different from the high-level laboratory research results in the past, the results of this AI revolution are rapidly landing and moving towards commercialization. According to Reuters, OpenAI‘s revenue in 2022 is expected to be only about $80 million. However, OpenAI said that by 2024, OpenAI’s revenue is expected to increase to $1 billion. Sequoia Capital Prediction: Generative AI tools such as ChatGPT allow machines to get involved in knowledge and creative work on a large scale, and are expected to generate trillions of dollars in economic value in the future.
At the GTC developer conference on the evening of March 21, NVIDIA founder and CEO Jensen Huang said, “We are in the iPhone moment of AI”

Commercialization of AIGC leverages the trillion-dollar AI market
AIGC (AI Generated Content) is artificial intelligence to automatically generate content, which can give full play to its technical advantages in terms of creativity, expressiveness, iteration, communication, and personalization to create a new form of digital content generation and interaction. The GPT series is a commercial direction of AIGC.
AIGC is also considered as a new content production method following UGC and PGC/UGC. UGC is user-generated content, which originated in the Web2.0 era, such as blogs, video sharing, Youtube and other application solutions; PGC/UGC refers to professionally produced content and career-generated content respectively, such as video income platform Youku and Tudou platform program “Rampage Comics” , “Never Expected”, or Douyin, Kuaishou and other user-generated content. AIGC is subversive in terms of creation costs, and has multiple advantages of cost reduction and efficiency increase, and is expected to solve the current problems of uneven PGC/UGC creation quality or reduce the spread of harmful content, while stimulating creativity and improving content diversity . In addition, OpenAI’s most expensive AIGC language model Da Vinci has 750 words per $0.02, and the price of AIGC graphical model is only $0.020.
The vigorous demand for content output efficiency and content consumption in the next generation of Internet business will drive the rapid development of AIGC. Combined with the predictions of Gartner and Acumen Research and Consulting, the AIGC penetration rate will reach 10% in 2025, and the AIGC market size will reach US$110.8 billion by 2030, corresponding to a CAGR of 34% in 2021-2030. Among them, conversational AI is expected to have a market size of US$3.4 billion in 2030, and only US$520 million in 2021. The current monetization models of AIGC enterprises are mainly: subscription payment (monthly subscription), pay-as-you-go (data request amount, calculation amount, number of pictures, number of model training times, etc.), in the future MaaS (model as a service) is expected to replicate the SaaS enterprise service route Ushered in the singularity of demand explosion.
The AI model arms race between China and the United States is escalating
The development of AIGC is inseparable from the AI model. AI models are initially trained for specific application scenario requirements (i.e. small models). The versatility of the small model is poor, and it may not be applicable to another application scenario, and it needs to be retrained, which involves a lot of parameter adjustment, tuning work and cost. At the same time, because model training requires large-scale labeled data, in some application scenarios, the amount of data is small, and the accuracy of the trained model is not ideal, which makes AI research and development cost high and inefficient.
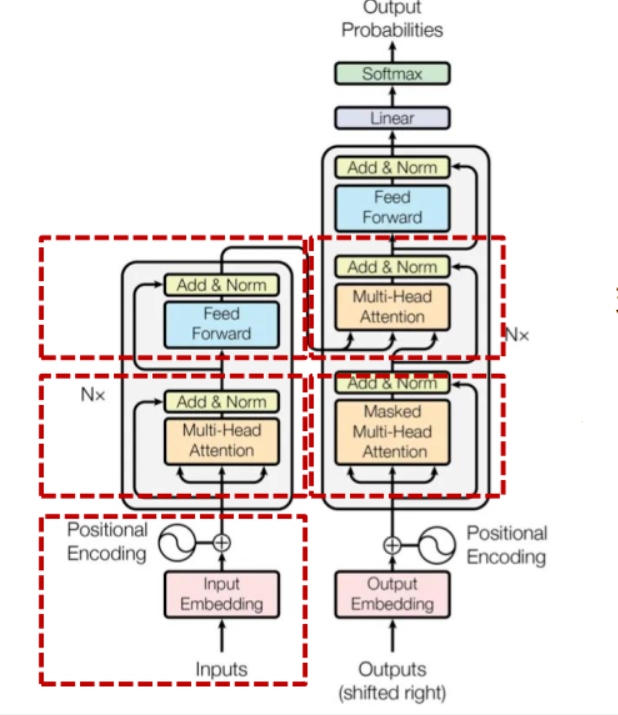
Until 2017, the Google Brain team launched the deep learning model Transformer, which uses a self-attention mechanism to differentially weight the importance of each part of the input data, and is mainly used in the fields of natural language processing (NLP) and computer vision (CV). At present, the pre-trained language model based on Transformer has become the mainstream in the field of NLP. ChatGPT is an excellent new model for NLP.

As we all know, GPT-4 is a multi-modal large model, so what exactly is multi-modal?
Modality is a social and cultural resource, and it is the meaning potential formed by material media through time. From the perspective of social semiotics, the cognition of modality can be sound, text and image. Human beings contact the world through various sensory organs such as eyes, ears, and touch. The source or form of each information can be called a modality. At the same time, the modality can also be the information that human beings get from the outside through their own sensory organs, such as smell, vision, hearing and so on. With the continuous development of machine learning and deep learning in the field of artificial intelligence, the continuous increase and update of research content has gradually given a new definition of modality, that is, the machine pair includes data representation mode, data collection mode, and data feature subject. A perceptual mode or information channel for external information.
Multimodal Machine Learning (MMML) studies machine learning problems involving different modal data, the general modalities are vision, text and sound. They often come from different sensors, and the data is formed and internally structured very differently. For example, an image is a continuous space existing in nature, and a text is a discrete space organized by human knowledge and grammatical rules. Multimodal machine learning refers to the ability to process, understand and integrate multi-source modal information through machine learning methods. The current popular research direction is the text-image model and its application.
With the explosion of ChatGPT and the launch of the multi-modal large model GPT-4, the China-US AI model arms race is escalating.
Relying on its first-mover advantages in model iteration and computing power, the United States focuses on the development of the infrastructure layer of large-scale model APIs, drives the development of the information industry and the scientific industry, and accelerates commercialization. The gap between Chinese companies and the United States is small in terms of AI data and large model parameters, but there is still a lot of room for improvement in model iteration and training, and most platforms focus more on AIGC content and applications.
The main large-scale models in the United States include OpenAI’s GPT-3, Anthropic’s Claude, Nvidia and Microsoft’s Megatron Turing-NLG, and Meta’s OPT. Among them, OpenAI has launched GPT-4, and it is said that the number of parameters will reach trillions. Google regards the GPT series of models as a red line, and is fully committed to the construction of the LLM (Large Language Model) model.
China’s large-scale models mainly include visual models of Baidu Wenxin, Huawei Pangu, Ali Tongyi, Tencent Hunyun, and SenseTime. Baidu launched the Wenxin large-scale model, which basically realizes cross-modal and multi-downstream and multi-field applications, and Wenxin Yiyan is currently online. Through model generalization, Huawei solves the problems of AI scale and industrialization that cannot be solved under the open model of traditional AI workshops.
Schematic diagram of Transformer’s Encoder-Decoder
On the whole, the United States still has a first-mover advantage in the model, which stems from long-term technical iteration and data accumulation. From the release of GPT 1.0 in 2018 to the release of GPT-3.5 and Instruct GPT in 2021, OpenAI has formed a series of massive data accumulation and training models, and the GPT-4 version released in March 2023 (it is said that the number of trillion-level parameters) . Although the parameters of some of China’s large models can reach hundreds of billions or even trillions, the data quality and training models still need time to improve.
Opportunities in the semiconductor industry: GPU dominates the 100 billion AI chip market
OpenAI predicts that in order to achieve breakthroughs in artificial intelligence scientific research, the computing resources required to consume will double every 3 to 4 months, and funding will also need to be matched by exponential growth. In terms of computing power, GPT-3.5 is trained on Microsoft Azure AI supercomputing infrastructure (a high-bandwidth cluster composed of V100GPU), and the total computing power consumes about 3640PF-days (that is, 1 trillion calculations per second, running for 3640 days ). In terms of big data, the data used for GPT-2 training is taken from highly praised articles on Reddit. The data set has a total of about 8 million articles and a cumulative volume of about 40G; the neural network of the GPT-3 model is based on more than 45TB of text The data is equivalent to 160 times that of the entire English version of Wikipedia. According to the data given by the qubit, the cost of training a large language model (LLM) to the GPT-3 level is as high as $4.6 million.
The latest GPT3.5 uses Microsoft’s specially built AI computing system in training, a high-performance network cluster composed of 10,000 Nvidia V100 GPUs, with a total computing power consumption of about 3640PFdays (PD), that is, if computing one quadrillion per second (1020) times, need to calculate 3640 days. The cost of purchasing a top-level Nvidia GPU is 80,000 yuan, and the cost of a GPU server usually exceeds 400,000 yuan. For ChatGPT, at least tens of thousands of Nvidia GPU A100s are needed to support its computing infrastructure, and the cost of a model training exceeds 12 million US dollars.
With the diversification of artificial intelligence application scenarios, new algorithms and models are constantly emerging, and the number of parameters in the model is increasing exponentially, and the demand for computing power is increasing. AI chips are the “heart” of AI computing power. According to WSTS data, the global artificial intelligence chip market size in 2020 is about 17.5 billion US dollars. With the maturity of artificial intelligence technology and the continuous improvement of digital infrastructure, the commercial application of artificial intelligence will increase, which will promote the rapid growth of the AI chip market. It is estimated that the global artificial intelligence chip market will reach 72.6 billion US dollars in 2025.
AI chips are mainly divided into three types, namely GPU, FPGA and ASIC chips. Different types of AI computing chips have their own outstanding advantages and applicable fields, which run through the stages of AI training and reasoning. At present, the application of CPU in the field of artificial intelligence is limited, mainly due to the insufficient computing power of CPU in AI training.
At present, GPU is still the leading chip for AI applications, mainly because it has powerful computing power and high general applicability, and is widely used in various graphics processing, numerical simulation and artificial intelligence algorithm fields. The low development cost can also be widely used in various vertical downstream fields in a short period of time, and the optimization and expansion can be accelerated.
In the discrete GPU segment, Nvidia dominates with an 88% share. NVIDIA GPUs are widely used in AI and machine learning because of their high performance and support for CUDA. Therefore, OpenAI mainly uses Nvidia GPUs to train and run its AI models such as GPT-3 and ChatGPT. According to public data, ChatGPT has imported at least 10,000 NVIDIA high-end GPUs.
Among the major domestic GPU listed companies, Jingjiawei is a leading company in the domestic display control market through independent research and development of GPU and large-scale commercial use. In addition, Haiguang Information, Cambrian and other companies have deployed GPU products. Affected by the U.S.’s export controls on China’s GPU chips, it is expected that the replacement of domestic GPU chips will advance rapidly.
In the field of accelerated computing GPU, the BR100 product released by domestic Biren Technology surpasses the NVIDIA A100 chip in FP32 single-precision computing performance, but does not support FP64 double-precision computing; the FP32 single-precision computing performance of Tianji 100 launched by Tianshu Zhixin achieves It surpasses the A100 chip, but it is lower than A100 in terms of INT8 integer computing performance; the DCU Z100 launched by Haiguang realizes FP64 double-precision floating-point computing, but its performance is about 60% of A100. Therefore, from the perspective of high-precision floating-point computing capabilities, the computing performance of domestic GPU products and foreign products still has a gap of more than one generation.
However, the performance of the GPU is not only reflected in the hardware, but the software level is especially important for the ecological layout. At present, domestic enterprises mostly use OpenCL for independent ecological construction, but this requires a lot of time. Compared with AMD, which started to build the GPU ecosystem in 2013 and launched the ROCm open software platform for general-purpose computing nearly 10 years later, the gap between domestic manufacturers and Nvidia’s CUDA ecosystem in terms of software and ecology is more obvious than that of hardware.

Product layout of global AI computing platform giants
Nvidia is currently the global leader in AI computing platforms, and its product matrix includes four layers: hardware, system software, platform software, and applications. In terms of hardware, the bottom layer is based on three types of chips: CPU, GPU, and DPU, forming three pillars of computing power; at the system level, a wide variety of systems are deployed from the cloud to the edge, such as RTX (cloud game server), DGX (one-stop AI solution), HGX (AI supercomputing platform), EGX (edge AI computing platform), OVX (digital twin simulation), etc., provide hardware infrastructure for developers. At the platform software level, Nvidia provides developers with 150 acceleration library services, involving machine learning, neural networks, computer vision, genetic testing and other subdivided technical fields. In terms of application, Nvidia has created a series of AI application frameworks for specific fields, such as MODULUS (physical machine learning framework), RIVA (speech AI application), Isaac (robot platform), etc. These frameworks are based on NVIDIA HPC, NVIDIA AI and NVIDIA Omniverse platform build. Each level is open to computer manufacturers, service providers and developers, and the integrated software and hardware solutions are suitable for a wide range of downstream fields.
NVIDIA builds an accelerated computing platform ecosystem based on GPU, DPU and CPU, creating core technical barriers.
In terms of GPU, the main product Tesla GPU series has a fast iteration speed. From 2008 to 2022, 8 types of GPU architectures have been launched successively, and new architectures have been launched in an average of more than two years, and new products have been launched in half a year. The ultra-fast iteration speed makes Nvidia’s GPU performance at the forefront of the AI chip industry, leading the revolution in the field of artificial intelligence computing.
In terms of DPU, Nvidia strategically acquired Mellanox, an Israeli supercomputer Ethernet company, in 2019, and used its InfiniBand (infinite bandwidth) technology to design the Bluefield series of DPU chips to make up for the lack of data interaction in its ecology. InfiniBand, like Ethernet, is a standard for computer network communications, but with extremely high throughput and low latency, and is often used to interconnect supercomputers. Nvidia’s Bluefield DPU chip can be used to share the CPU’s network connection computing power requirements, thereby improving the efficiency of cloud data centers and reducing operating costs.
In terms of CPU, self-designed Grace CPU and launched Grace Hopper super chip to solve the problem of memory bandwidth bottleneck. Traditional data centers using x86 CPUs will be limited by PCIe bus specifications, the bandwidth from CPU to GPU is small, and computing efficiency is affected; while the Grace Hopper super chip provides a consistent memory model combining self-developed Grace CPU+GPU, which can be used NVIDIA NVLink-C2C technology transmits quickly, and its bandwidth is 7 times that of the 5th generation PCIe bandwidth, which greatly improves the operating performance of the data center.
NVIDIA GPUs are widely used in AI and machine learning due to their high performance and support for CUDA. OpenAI mainly uses Nvidia GPUs to train and run AI models such as GPT-3 and ChatGPT. According to public data, ChatGPT has imported at least 10,000 NVIDIA A100s. The NVIDIA A100, which is the first release of the Ampere architecture, can increase the amount of HPC computing by 2.5 times compared to the Tesla V100. The unit price of a single A100 is about 80,000 yuan.
The technological innovations incorporated in the H100 can accelerate the speed of large language models, 30 times faster than the A100, and provide industry-leading conversational AI acceleration (similar to ChatGPT). Launched on March 22, 2022, the H100 is equipped with 80 GB of video memory, equipped with NVIDIA Hopper HPC GPU, and adopts TSMC’s 4nm process, with a unit price of more than 200,000 yuan. H100 is equipped with the fourth-generation Tensor core and Transformer Engine with FP8 accuracy, which can dynamically manage and select FP8 and FP16, and automatically process the automatic conversion between FP8 and FP16 for each layer of the model. Compared with the current A100 architecture, it can make AI training A 9x improvement and a 30x improvement in inference performance without compromising accuracy.
At present, ASUS, Atos, Dell, INGRASYS, Gigabyte, Lenovo and Supermicro (Supermicro) and many other partners of NVIDIA have launched products equipped with A100/H100, which have been deployed on major clouds such as AWS, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure. used on the platform.
Post time: Mar-30-2023